
Common code coupling mistakes
What is code coupling? And how to avoid the common mistakes
Code coupling is the degree to which two software modules or packages depend on each other. In this post we describe coupling and the common mistakes that lead to coupled code.
The degrees of coupling
You might have heard someone say
“Coupling is bad” – a software dev
Well, this isn’t strictly true. Firstly because there are degrees of coupling. To say ‘coupling is bad’, we’re implicitly saying that high coupling is bad.
Coupled code – even highly coupled code – isn’t inherently bad code. We call high coupling between two software packages bad because the coupling creates bad side effects. So to be more specific, we can say high coupling creates bad side effects.
What are the bad side effects of coupled code?
The biggest side effect is ‘scope of change’. This is how far a single change cascades through a codebase.
In highly coupled code one package or module cannot easily change without changes in another package. This increases the scope of your changes, the changes that you wanted to make in one package start to cascade into other software packages.
An increasing scope of change is bad for both
- the obvious reason; literally more code to change
- the implied reason; with more code changes comes a higher chance of introducing a bug and a slower time-to-delivery.
It’s because of the scope of change that we say that highly coupled code causes software bugs. When more accurately we can say; highly coupled code creates cascading changes in a codebase, increasing the chance of bugs and decreasing the speed of delivery.
To avoid coupled code, we can look for the common code coupling mistakes.
Common code coupling mistakes
Each of these examples are a mistake in the organisation of code – leading to code coupling. Each example is a mistake in identifying which code should belong together. Which affects our code’s coupling. And higher coupling leads to harder to change code.
Mistake #1 — Rails-style packaging, or the everything import
In this example we’ve organised our code into layers; controller, service, repository. I call this code organisation the ’everything import’ because no code is hidden inside a package. All the code is public or exported and used by some other package.
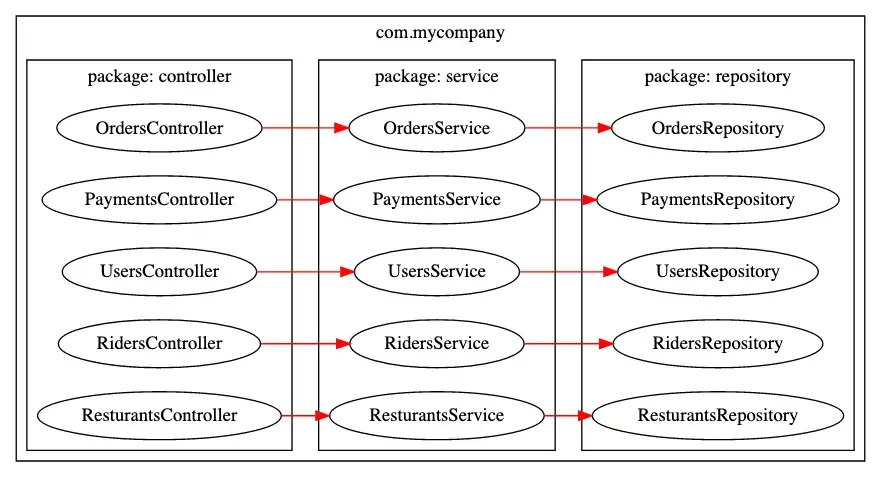
If we remember from earlier, code coupling is the degree two which two packages depend on each other. We can see in our diagram each package heavily depends on the layer below it. There’s little separation and isolation between the packages. This code is coupled.
Mistake #2 — The single import
The second common mistake is when most of the code lives in a package together, but one or two types/classes are in the wrong package.
In the diagram the it’s the OrdersRepository that’s in the wrong package.
All our orders code lives together, except for that one class.
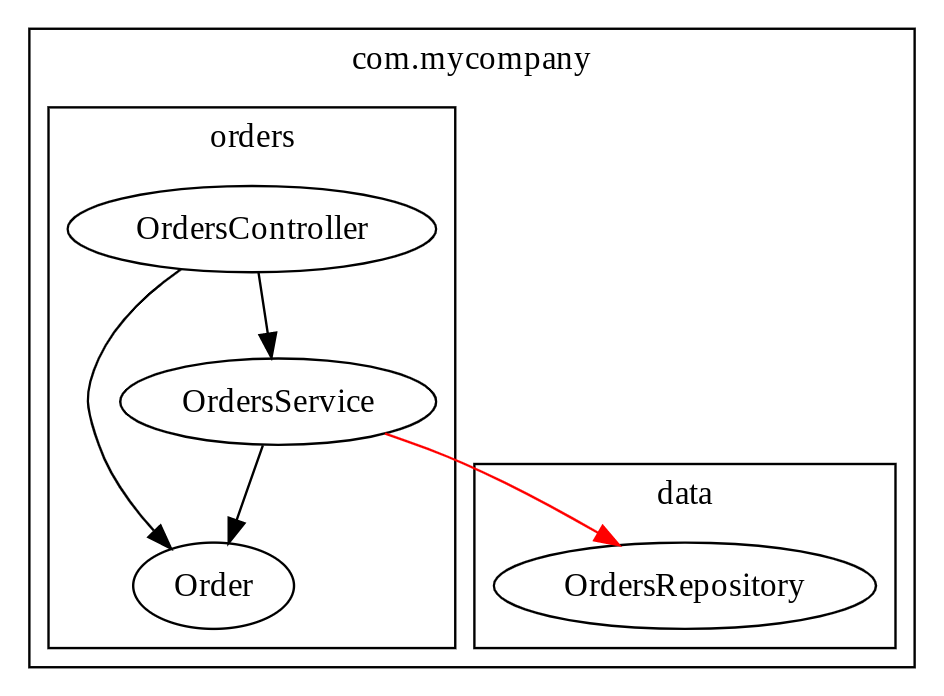
This is common when code is going through substantial refactoring or reorganisation. With most code review tools it’s easy to see the content of a file, but harder to see how that file interacts with the other files in the project. Because it’s hard to see the interactions between files it’s easy for one file to get left behind, causing the single import problem.
Leaving behind a single type of class often means that class doesn’t benefit from the package level hiding, and is open to be exported by other code. This increase the likelihood that other code will import that code, which increases the likelihood of a future cascading change.
Mistake #3 — The skip level import
The skip level import happens when one package provides an abstraction over some other lower level packages.
For example, in a system that sends notifications; we might have push notifications, email notifications, websocket notifications, and more.
The different types of notifications could be abstracted by a NotificationService, that delegates to the type of notification.
Our NotificationService could be used by Payments, Riders and Orders.
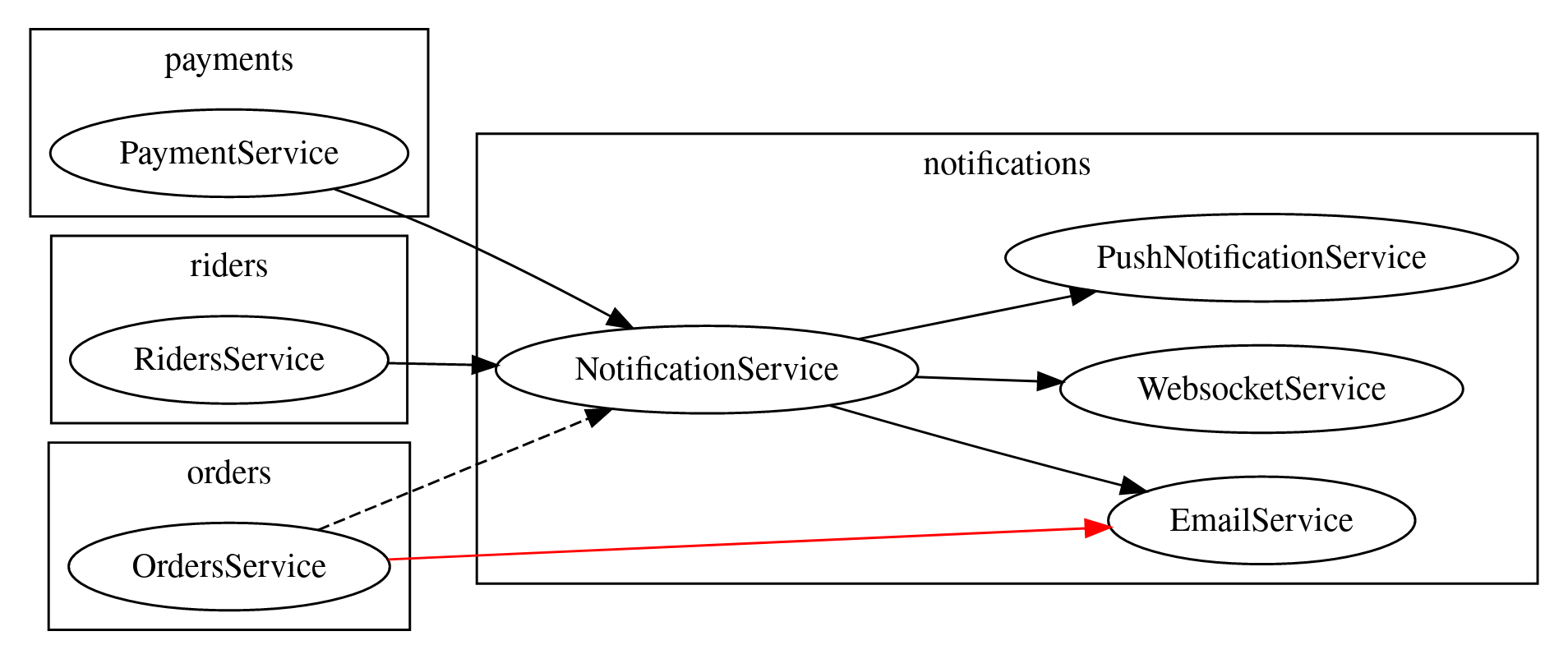
In the diagram, we can see an example of the skip-level import.
The OrdersService should be making use of the NotificationService abstraction, but instead it is skipping a level and using the EmailService directly.
This breaks the benefits of the abstraction, as the NotificationService isn’t hiding the notification details of email sending from the OrdersService.
The code in EmailService is now harder to change, as both OrdersService and NotificationService depend on it.
If the code didn’t suffer from this skip-level import, we could change the internals of sending notifications without the consumers of this package needing to change.
But because of the skip level import where OrdersService uses EmailService it’s hard to change the internals of either the EmailService or the notifications package.
Mistake #4 — The double direction import
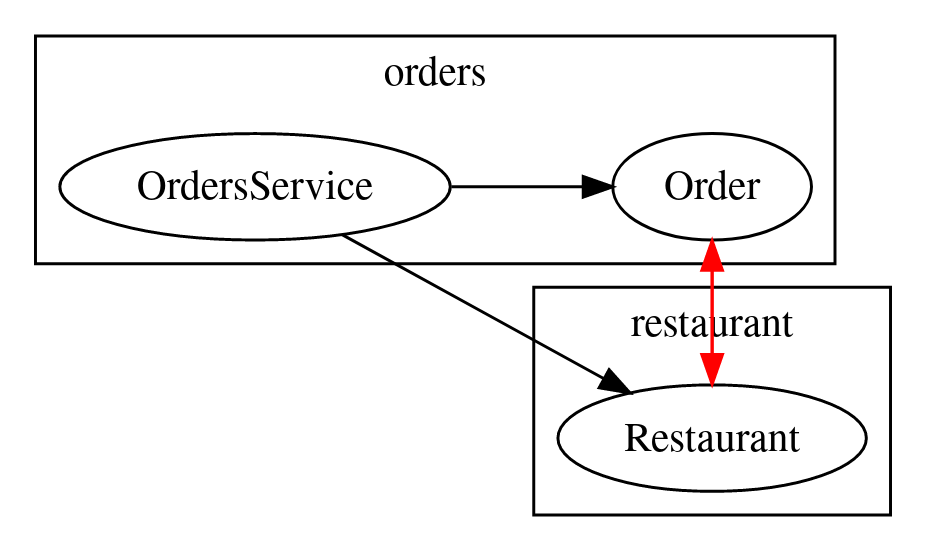
The double direction import is a type of circular dependency, where two types rely on each other. Here an Order might be for a Restaurant and a Restaurant might have an Order.
The hierarchy is confused. Does an Order know the Restaurant or the Restaurant know the Order?
In many languages this code will fail to compile when this happens.
But the same problem can present more subtly when the Order and the Resturant just reference each other by identifier rather than by an instance of their type.
Mistake #5 — The mispackaged ‘god model’
Many applications have a small number of data models that are used extensively throughout the application.
We call these ‘god models’. They often permeate all parts of our application and are core to the business problem we are trying to solve.
This creates code coupling, as changes to that core model cascade throughout the rest of the application.
In this example payments, riders, and restaurants all rely on an Order. So Order becomes our mispackaged ‘god model’.
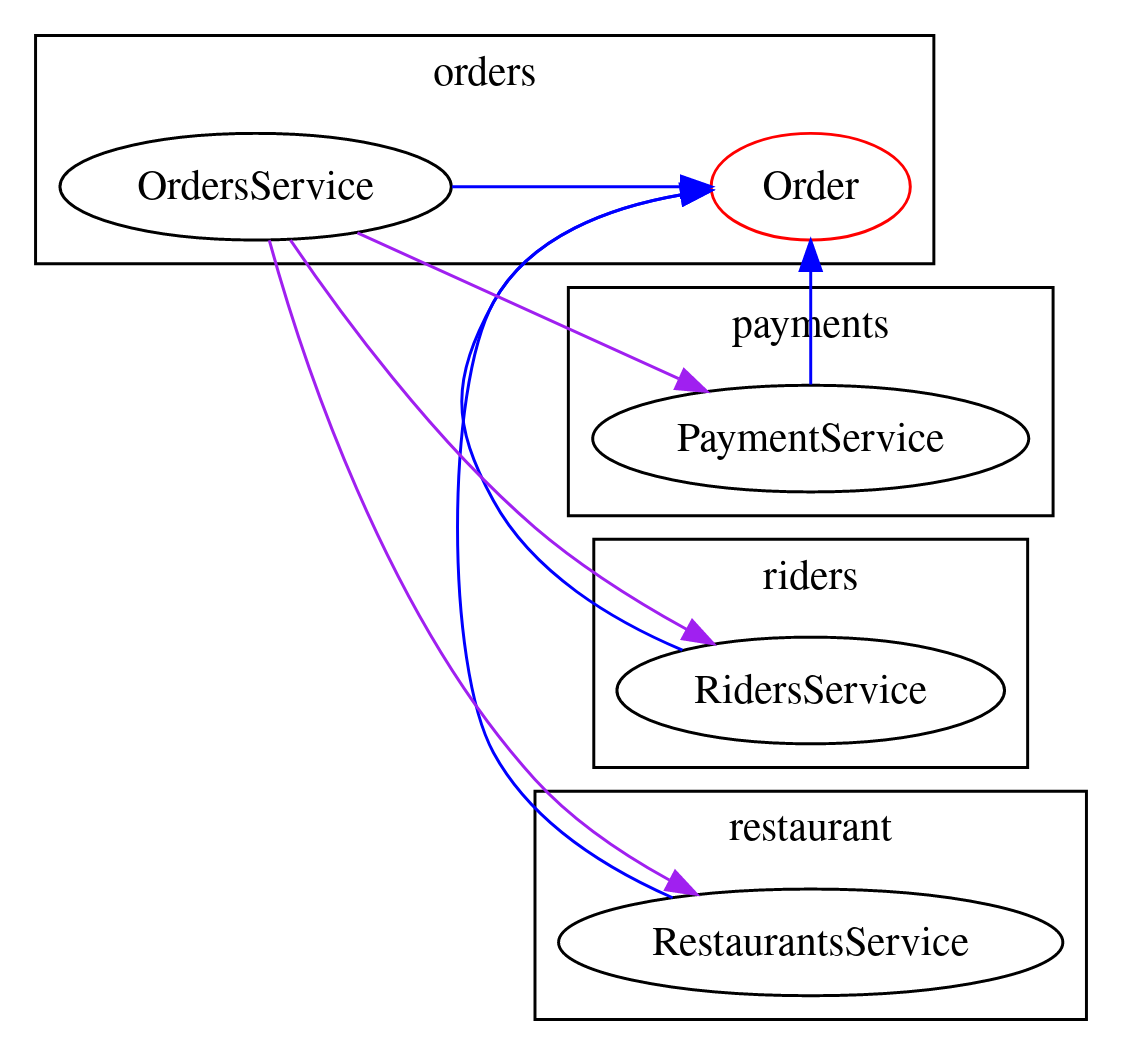
There are two ways you could solve this;
The first option is to accept that Order is a god model, and move it to a “root” or “domain” package that represents it as a god model.
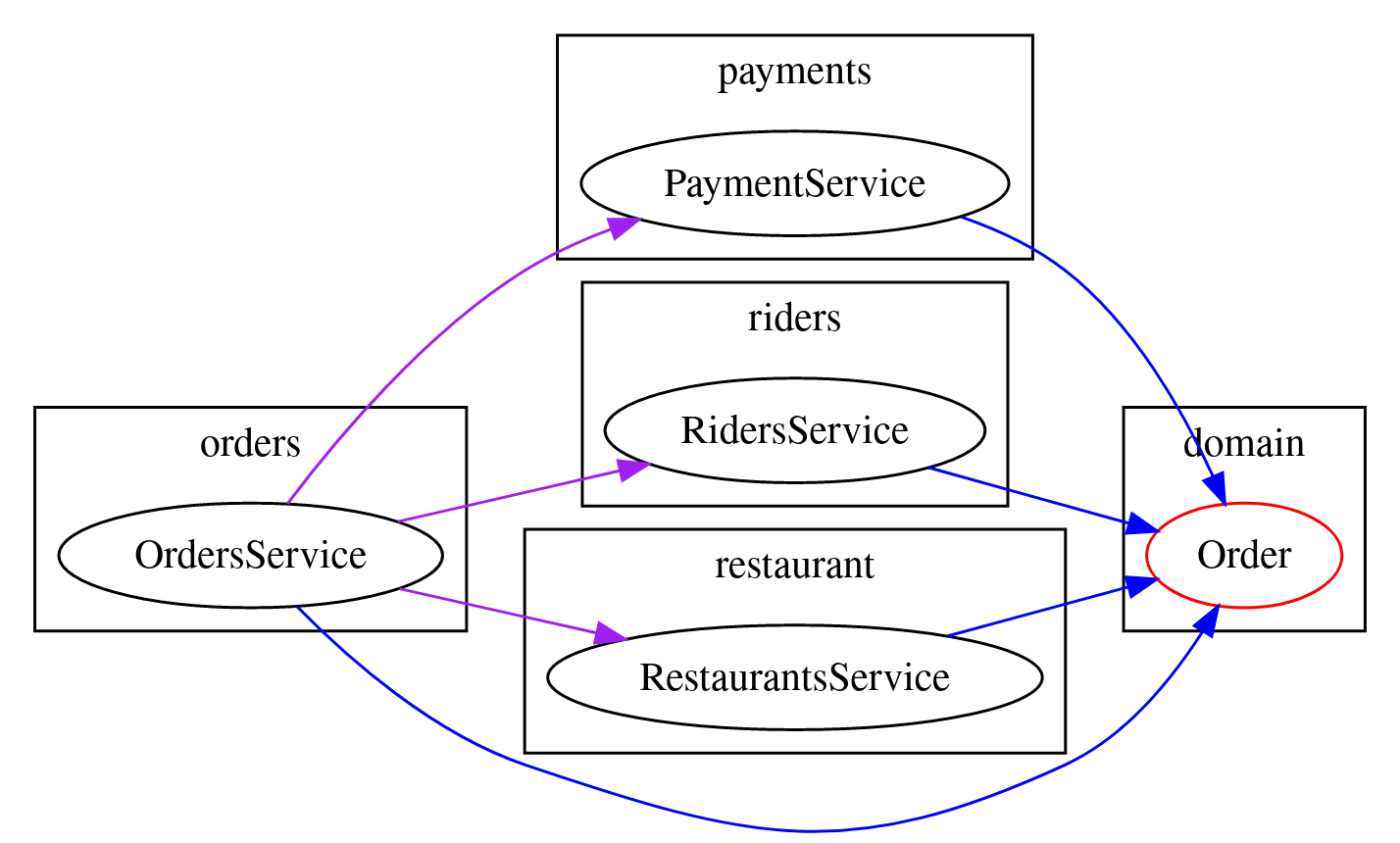
In this redrawn diagram we’ve moved the god model into a shared domain package that can be imported by all the other packages.
This domain package only holds the shared types, and no behaviour.
The second option is to invert the remaining dependencies, so that OrdersService isn’t importing the service implementations.
In this example the orders package defines interfaces for the behaviours it needs from PaymentsService, RidersService and RestaurantsService.
Each of the types in the orders package can make use of the Order god model.
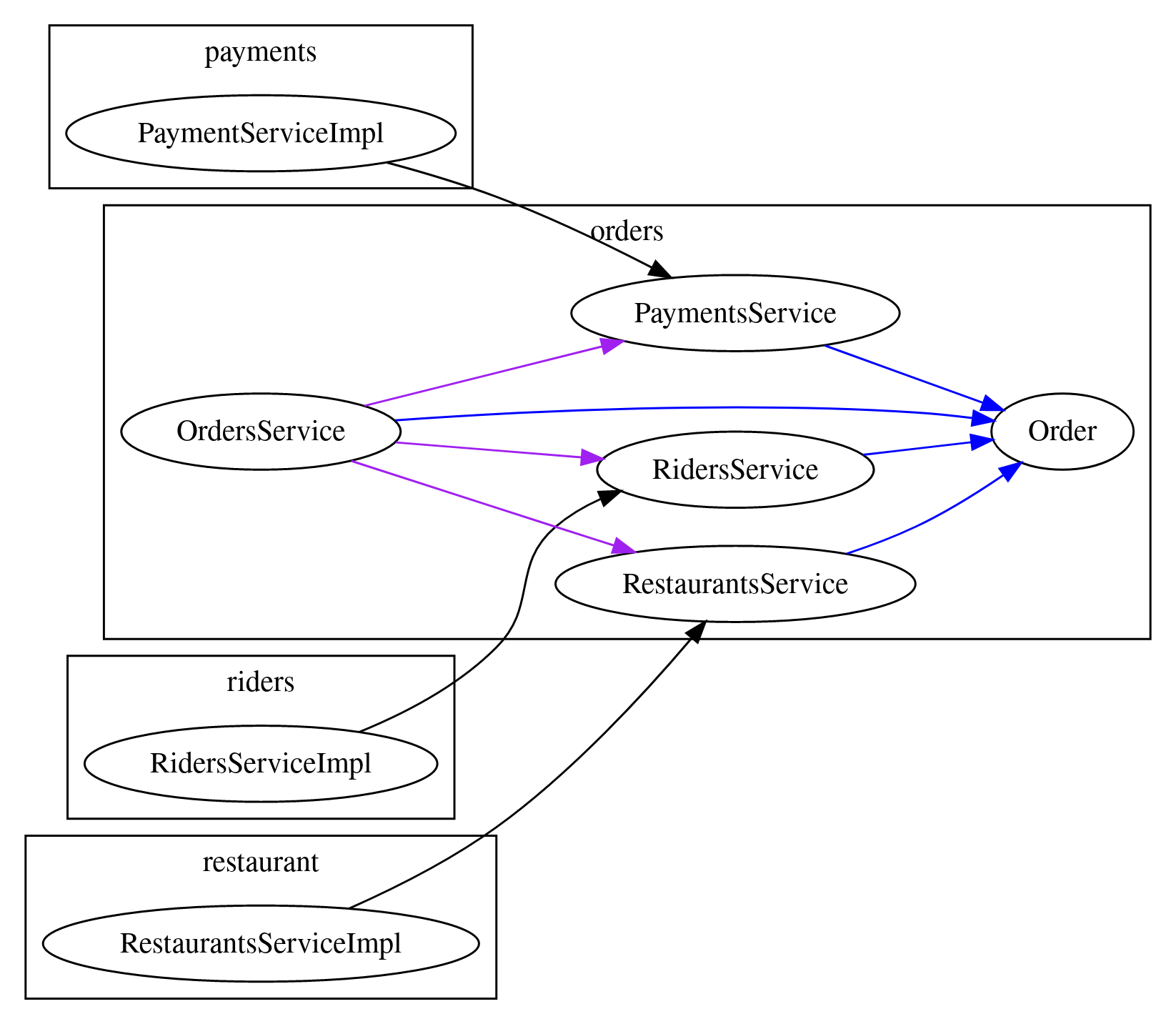
The actual implementations of these interfaces live in other packages:
RestaurantsServiceImplimplementsResturantsServicePaymentsServiceImplimplementsPaymentsServiceRidersServiceImplimplementsRidersService
This is called the “ports and adaptors” or “onion” architecture.
Why are these mistakes common?
These code coupling mistakes are common because they are hard to see.
Most code review tools show you the content of the files, but don’t really show you how those files interact with each other. The common file-tree browser structure doesn’t expose these 5 common code coupling mistakes.
These mistakes are relatively easy to rectify and check for, assuming that you can see them. This is why we built PackageMap. PackageMap parses your source code into a diagram like the examples in this post. Using this diagram you can easily spot the code coupling mistakes we’ve covered here.
And once you can see how your code is structured, it’s much easier to identify and fix these code coupling mistakes.